Ergebnisse
In unten stehender Tabelle sind die besten Ergebnisse aller Algorithmen mit den jeweiligen Datengrundlagen abzulesen. Es ist zu erkennen, dass die ungefilterten Bilder innerhalb des CNN, mit einer Accuracy von 54 %, das beste Ergebnis erzielten. Nicht viel schlechter schneidet das KNN mit den HOG-Features, mit einer Accuracy von 51,5 %, als Datengrundlage ab. Interessant ist ebenfalls, dass das Clutering mit den HOG-Features ein überraschend gutes Ergebnis erzielt, und zwar 37,3 % Accuracy, welches durch den geringen Aufwand der Vorbereitung für manche Forschungsfragen eventuell bereits ausreichen könnte. Es ist zu beachten, dass die hier vorgestellten Ergebnisse nicht das Ende, sondern lediglich den Anfang der Optimierung der jeweiligen Modelle darstellen. Durch präzise Optimierung sind die Ergebnisse vermutlich noch weiter zu verbessern. Insgesamt lässt sich festhalten, dass die Klassifizierung einzelner Zeichen durch Methoden des maschinelles Lernens, durchaus möglich ist.
| Feature-Set | Threshold | Accuracy | Precision macro | Precision weighted | Recall macro | Recall weighted | F1 macro | F1 weighted |
|---|---|---|---|---|---|---|---|---|
| Clustering | ||||||||
| image_features | 8 | 4.96% | 0.39% | 1.90% | 0.75% | 4.96% | 0.43% | 2.48% |
| image_features_annotations | 14 | 8.79% | 2.91% | 5.32% | 2.61% | 8.79% | 2.12% | 5.65% |
| hog_features | 20 | 37.26% | 26.21% | 36.39% | 22.02% | 37.26% | 21.61% | 34.52% |
| images | 14 | 23.32% | 14.56% | 21.58% | 11.48% | 23.32% | 11.35% | 20.50% |
| images_filtered | 14 | 22.10% | 10.59% | 18.08% | 10.94% | 22.10% | 9.94% | 18.73% |
| CNN | ||||||||
| images | 20 | 54.02% | 46.70% | 54.91% | 40.57% | 54.02% | 40.95% | 52.73% |
| images_filtered | 14 | 50.78% | 41.92% | 50.93% | 37.07% | 50.78% | 37.11% | 49.24% |
| KNN | ||||||||
| annotations | 14 | 4.97% | 0.41% | 1.44% | 0.86% | 4.97% | 0.26% | 1.51% |
| image_features | 20 | 3.28% | 1.07% | 2.24% | 1.13% | 3.28% | 0.84% | 2.27% |
| image_features_annotations | 20 | 7.14% | 0.19% | 0.41% | 1.92% | 0.71% | 0.15% | 0.42% |
| hog_features | 20 | 51.53% | 46.18% | 52.15% | 36.83% | 51.53% | 37.95% | 49.54% |
| images | 10 | 29.70% | 29.37% | 34.85% | 17.41% | 29.70% | 18.40% | 27.93% |
| images_filtered | 14 | 31.73% | 27.48% | 33.05% | 18.97% | 31.73% | 19.47% | 29.21% |
| Random-Forest | ||||||||
| annotations | 20 | 5.12% | 0.41% | 1.58% | 1.21% | 5.12% | 0.43% | 1.57% |
| image_features | 20 | 9.44% | 1.38% | 4.20% | 1.92% | 9.44% | 1.20% | 4.80% |
| annotations_image_features | 20 | 11.84% | 4.82% | 8.21% | 4.01% | 11.84% | 3.45% | 7.92% |
| hog_features | 20 | 36.21% | 29.47% | 38.74% | 14.86% | 36.21% | 16.19% | 30.65% |
Zusätzlich zu der Bestimmung eines geeigneten Algorithmus und einer idealen Datengrundlage galt es, die Ergebnisse zu untersuchen, um Auffälligkeiten herauszuarbeiten. Diese bestanden aus den genannten, allgemeinen Metriken und einer Kofusionsmatrix, die die Metriken für jedes einzelne Zeichen aufführt.
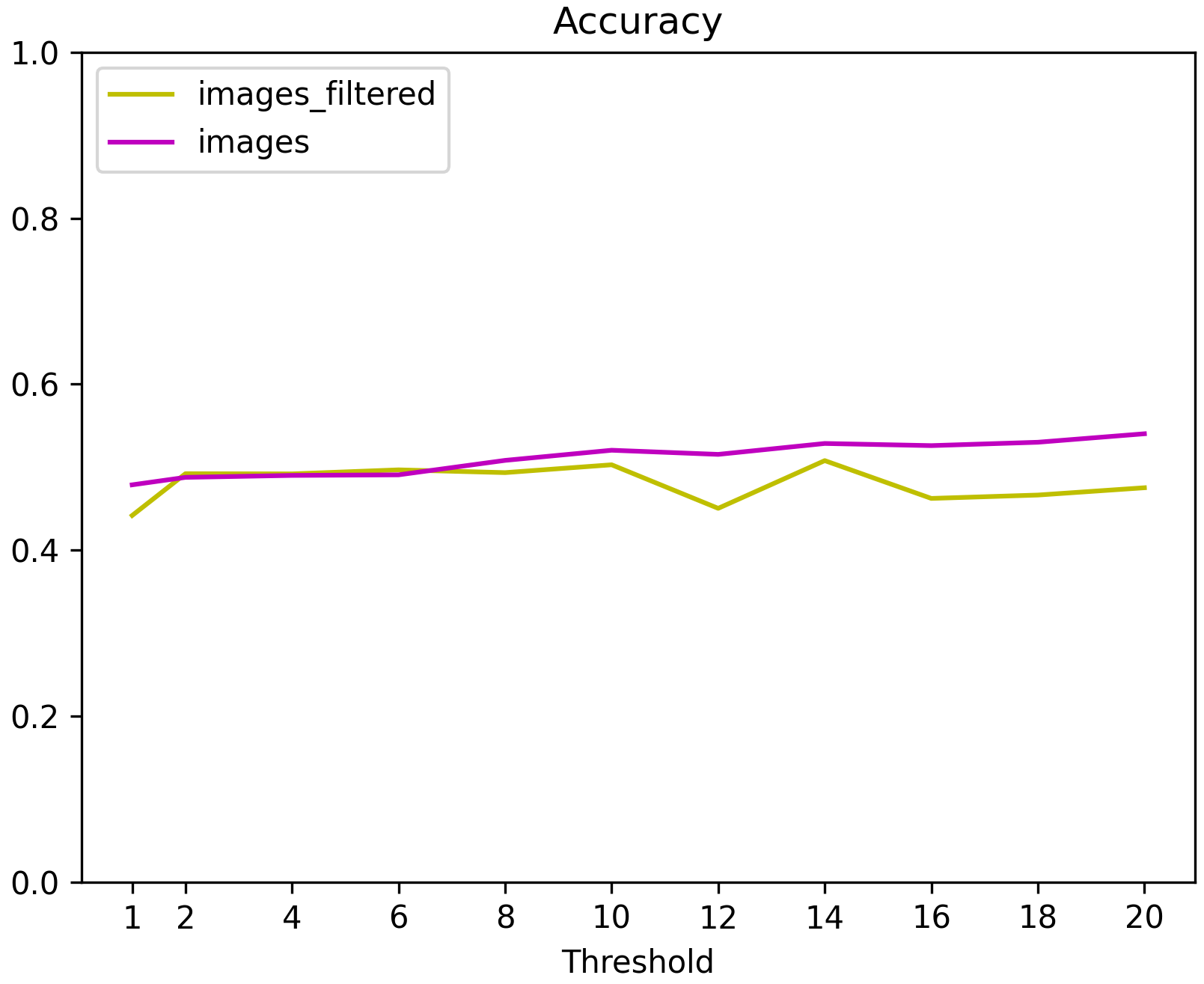 Darstellung der Accuracy des CNN für jede Datengrundlage in Bezug zu dem Threshold | 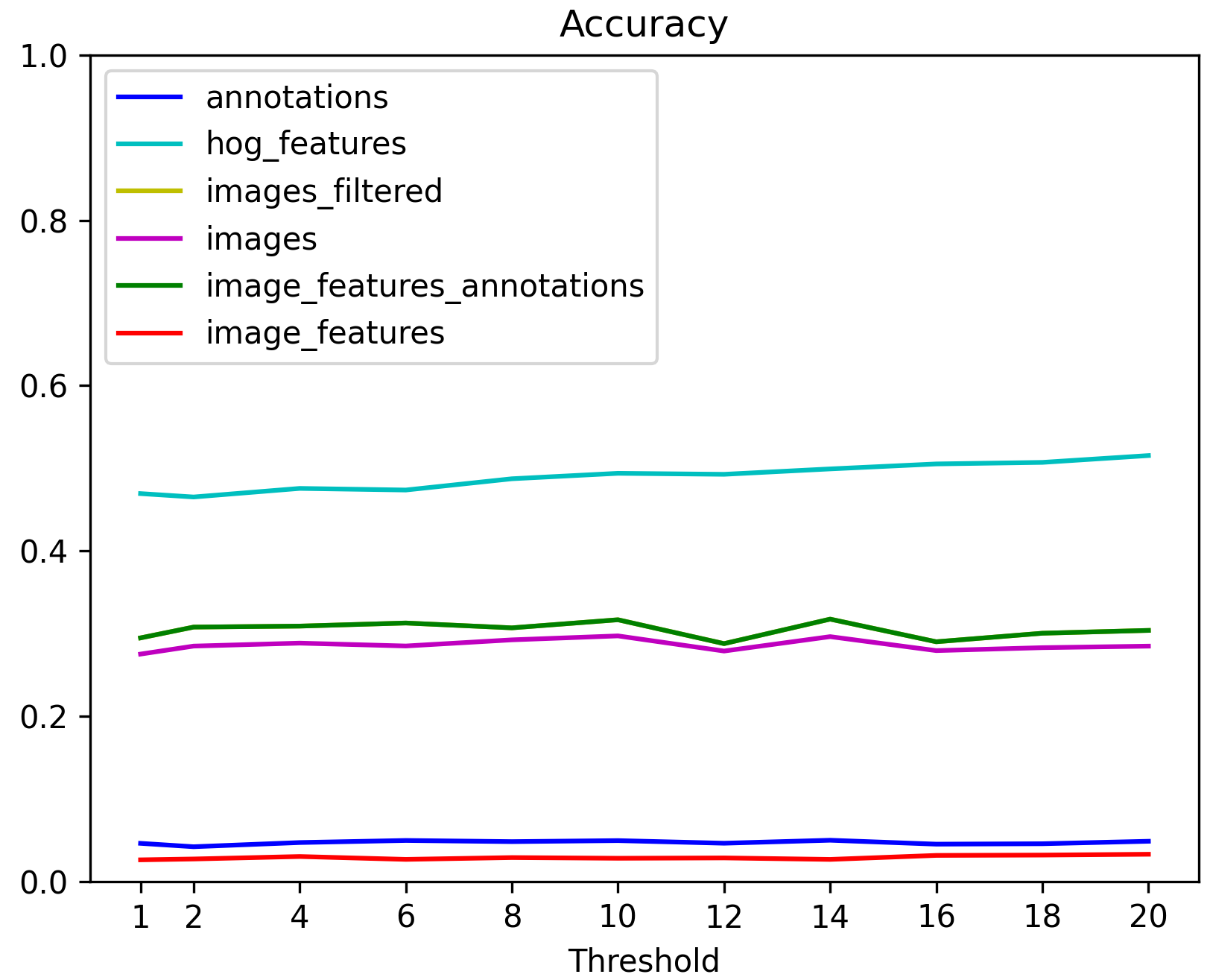 Darstellung der Accuracy des KNN für jede Datengrundlage in Bezug zu dem Threshold |
Aus den dargestellten Diagrammen konnte kein idealer Threshold-Wert bestimmt werden, weshalb zusätzlich die Konfusionsmatrix analysiert wurde, um herauszuarbeiten, inwiefern die Häufigkeit eines Zeichens Einfluss auf die Klassifizierung hat. Dazu wurden im speziellen die Experimente des CNN mit den Bildern selbst und das Modell des KNN-Algorithmus mit den HOG-Features betrachtet. Beide mit einem Threshold von 20. Diese Ergebnisse zeigen, dass generell eine höhere Anzahl von Zeichen im Datensatz mit einer höheren Klassifikationsgenauigkeit (Accuracy) korreliert. Dies gilt für beide Modelle. Es gibt jedoch Ausnahmen, denn trotz häufigem Vorkommen, erreichten manche Zeichen keine hohe Accuracy, während seltene Zeichen einen überraschend hohen Wert erzielten.
Im Detail:
- Zeichen mit einer Accuracy von über 50% waren im Mittel häufiger im Datensatz vertreten. Der Median der Häufigkeiten eines Zeichens liegt bei beiden Modellen bei etwa 94 Zeichen.
- Für Zeichen mit einer Accuracy von über 70% liegt der Median im Datensatz bei 131 für das CNN und 132 für KNN.
- Bei Zeichen mit einer niedrigen Accuracy (unter 50%) lag der Median bei 43 .
Ebenfalls ist eine Korrelation zwischen der Anzahl der Zeichen im Datensatz und der Häufigkeit ihrer Nutzung für Falschklassifikationen zu erkennen, welche stärker ausgeprägt war, als die Korrelation der Häufigkeit und einer hohen Accuracy. Interessanterweise hatten diese Zeichen trotzdem eine überdurchschnittliche Klassifikationsgenauigkeit.
Werden die 40 Zeichen mit der höchsten Accuracy beider Modelle verglichen, teilen sich diese dabei 17. Dies zeigt, dass beide Modelle unterschiedlich gut verschiedene Zeichen erkennen. Beim direkten Vergleich der Zeichen, die als Falschklassifizierung genutzt wurden, sind in den 40 am häufigsten verwendeten 27 Zeichen identisch. Die Nutzung für Falschklassifizierung korreliert ebenfalls stärker mit der Häufigkeit der Zeichen im Datensatz, was erklären könnte, warum hierbei mehr Zeichen von beiden Modellen auf die gleiche Weise falsch verwendet wurden. Dadurch ist ebenfalls nicht abschließend festzustellen, welche Zeichen besondere Probleme bei der Klassifikation hervorrufen, da dies in dieser Arbeit in erster Linie durch die Häufigkeit des jeweiligen Zeichens ausgelöst zu werden scheint.
Zusammengefasst deutet die Analyse darauf hin, dass die Anzahl der Zeichen im Trainingsdatensatz einen signifikanten Einfluss auf die Klassifikationsgenauigkeit hat. Obwohl häufig vorkommende Zeichen tendenziell besser klassifiziert wurden, ist dies kein absolutes Kriterium für eine erfolgreiche Klassifizierung, da es sowohl positive als auch negative Ausreißer gibt. Eine Angleichung der Verteilung der Klassen könnte jedoch das Problem der Falschklassifizierung verbessern, da dadurch die starke Korrelation dieser mit der Anzahl der Zeichen verringert werden könnte. Dies könnte zum einen durch die Erhebung weiterer Daten als Grundlage geschehen oder durch die manuelle Vervielfältigung vorhandener Bilder. Dies in Kombination mit einer Optimierung der Modelle und der Erhebung der Bildeigenschaften könnte zu deutlich besseren Ergebnissen führen. Ebenfalls wäre es möglich beide Modelle zu kombinieren, um die Stärken zu Nutzen. Es konnte festgestellt werden, dass beide Modelle unterschiedlich gut unterschiedliche Zeichen erkannten. Durch die Kombination könnte dies genutzt werden, um die Klassifikation im Allgemeinen zu verbessern.