Methodik
Methodisch orientiert sich die Arbeit an dem Konzept von Pedro Domingos, der einen Zyklus aus Repräsentation, Evaluation und Optimierung vorschlägt. Fokus liegt hierbei in dieser Arbeit auf der Repräsentation und Evaluation. Die Optimierung erfolgt insofern, dass repräsentative Ergebnisse erreicht werden, um eine Einschätzung über Weiterentwicklungen geben zu können. Um ein geeignetes Modell für die Lösung eines bestimmten Problems zu entwickeln, muss zunächst ein Algorithmus gewählt werden, der als Repräsentation dient. In dieser Arbeit wurden die Algorithmen K-Means, KNN, Random-Forest und CNN als Repräsentation getestet, um diesen Auswahlprozess für zukünftige Arbeiten zu erleichtern. Die präzise Evaluation dieser soll damit als Grundlage für die Optimierung in zukünftigen Arbeiten dienen.
Eine Einschätzung über den Erfolg eines Algorithmus geschieht durch die Bewertungsmetriken Accuracy, Precision, Recall und dem F1-Score. Der Fokus liegt allerdings bei der allgemeinsten Metrik, der Accuracy, welche beschreibt, wie viel Prozent der Zeichen des genutzten Datensatzes korrekt klassifiziert wurden.
| Threshold | Zeichenanzahl | Klassen |
|---|---|---|
| 1 | 28057 | 699 |
| 2 | 27855 | 598 |
| 4 | 27408 | 470 |
| 6 | 27098 | 412 |
| 8 | 26772 | 369 |
| 10 | 26507 | 341 |
| 12 | 26236 | 317 |
| 14 | 26004 | 300 |
| 16 | 25709 | 281 |
| 18 | 25273 | 256 |
| 20 | 25021 | 243 |
Datengrundlage
Die Datengrundlage bestand aus Bildern einzelner Keilschriftzeichen, welche bereits annotiert waren und aus dem MeiCuBeDa Datensatz stammen (Mara, Hubert und Timo Homburg. 2023). Das heißt, dass sowohl die Transliteration der jeweiligen Zeichen vorhanden ist, als auch die Metainformationen der Epoche, der Sprache und das Herkunftsland der Tafel, auf der das jeweilige Zeichen stand. Aus den Bildern selbst wurden bestimmte Eigenschaften berechnet, die als Grundlage für die Klassifizierung getestet wurden, um den besten Ansatz zu finden. Dies waren zum einen Textureigenschaften, in der Arbeit unter dem Begriff Image-Features zusammengefasst, und zum anderen sogenannte HOG-Features. HOG-Features sind Eigenschaften, die mithilfe eines “Histogram of oriented gradients” Kontur- und Formeigenschaften von Objekten in Bildern beschreiben. Um diese zu berechnen, wurden die Bilder zunächst, wie unten zu sehen, verarbeitet. Die entstandenen schwarz-weiß Bilder der Keilschriftzeichen wurden, wie die unverarbeiteten Bilder auch, als Grundlage für die Klassifizierung genutzt. Um eine ideale Anzahl an Zeichen pro Klasse zu finden, wurden mehrere Experimente mit unterschiedlichen Thresholds durchgeführt, die den Datensatz beschränken. Zeichen, deren Anzahl gleich oder kleiner als der Threshold waren, wurden für das jeweilige Experiment ignoriert. Welche Auswirkungen dies auf die Anzahl der Klassen und Zeichen hatte, ist in obiger Tabelle abzulesen. Dadurch wird ebenfalls klar, wie unausgeglichen die Verteilung der Daten im Datensatz war, da bei einem Threshold von 20 über 400 Klassen aussortiert wurden.
 Bild des Zeichens 1(asz) | 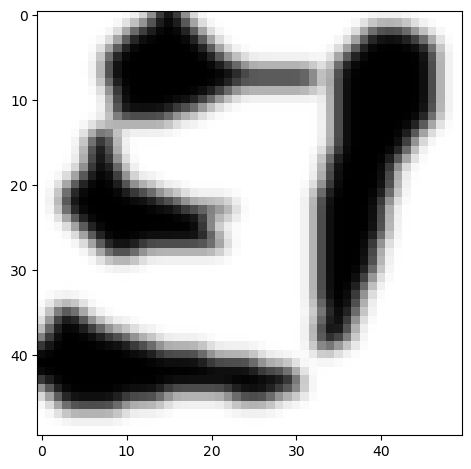 Bild des Zeichens 1(ban2) | 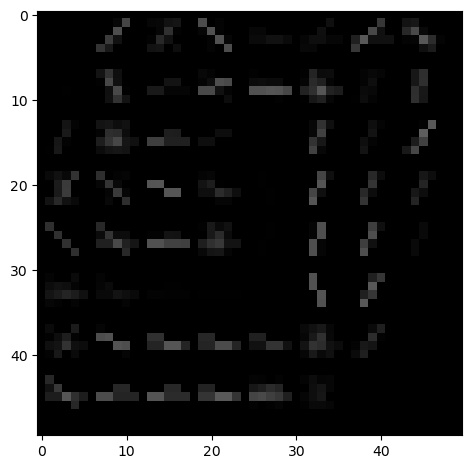 Bild des Zeichens 1(ban2) |
Es ergaben sich damit folgende Datengrundlagen, welche, soweit möglich, mit jedem Algorithmus und jedem Threshold getestet wurden: Die Annotationen, die Image-Features, die Annotationen in Kombination mit den Image-Features, die HOG-Features und die Bilder anhand der Pixelwerte in gefilterteter und ungefilterter Form. Vor dem Erstellen und Evaluieren der Modelle, wurden alle Bilder zunächst auf eine Größe von 50*50 Pixel verkleinert, um den Verarbeitungsprozess zu beschleunigen. Dies kann zwar zu schlechteren Ergebnissen führen, dadurch das das Ziel jedoch keine perfekten Modelle, sondern leidiglich eine Einschätzung dieser ist, war dies nicht relevant, sondern ermöglichte, mehr Experimente durch die geringere Laufzeit durchzuführen.